Photo credit: Thorsten Ries.1
Kürzlich, genauer gesagt, auf der DHBenelux 2015, stand ich (einmal mehr) vor dem Problem, im Rahmen meines Forschungsprojekts zu Thomas Kling Textvarianz von nicht-normalisierten, natürlichsprachlichen Texten und den Zeitverlauf von Thomas Klings Projekt “Vorzeitbelebung” visuell eindrücklich darzustellen. Beide Aspekte sind so umfangreich in der Darstellung, dass sie nicht wirklich auf statische Folien zu bringen waren, dynamische, interaktive Lösungen mussten her.
Timeline: Für die dynamische Visualisierung des komplexen Zeitablaufs von Klings Schreibprojekt und der Chronologie der digitalen Textzeugen konnte ich mir gut mit vis.js helfen. Kleiner Tipp: Die Beispiele kann man alle sehr leicht mit “Speichern unter” auf den eigenen Rechner herunterladen und dann die HTML-Datei anpassen, die zugehörige Bibliothek wird gleich mit heruntergeladen.
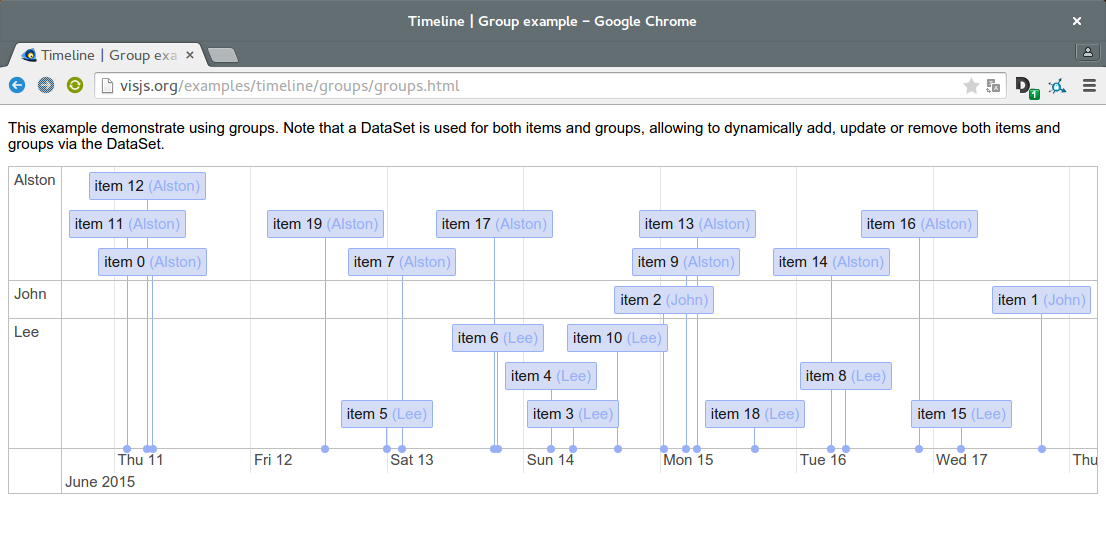 Photo credit:
Photo credit: Die besondere Schwierigkeit bei den zu vergleichenden Texten ist, dass es sich a) nicht um Code-Beispiele handelt, b) sie Textverschiebungen enthalten können und c) dass die Texte technisch bedingte Artefakte enthalten (etwa sinnwidrige Absätze), die am besten beim Vergleich unberücksichtigt bleiben. Außerdem sollen die Zeilen automatisch umgebrochen werden. Da es sich um geschütztes Material handelte, war es keine Option, Online-Lösungen zu benutzen – die Visualisierung musste also auf meinem eigenen Laptop stattfinden.
Was ist die Lösung? Für die oben genannten Anforderungen sind übliche diff-Softwares, die Code Zeile für Zeile vergleichen, überhaupt nicht geeignet. Bei früheren Vorträgen habe ich Diffuse verwendet, weil es n-way diff bietet und somit auch zum Vergleichen multipler Versionen in großen Textprojekten geeignet ist. Bei diesem Projekt allerdings waren die Anzahl der Versionen und die Textlänge so groß und die Texte so wenig normalisiert, dass dieser Ansatz sich selbst ausschloss und ich zu “einfacheren” 2-Wege-Diffs zurückkehrte.
Was den reinen Textvergleich angeht, ist Juxta bzw. JuxtaCommons (beta) eigentlich gut geeignet – allerdings ist Juxta schon recht alt und sieht unter Java auf Linux schlicht nicht präsentabel aus, auch ist die Synchronisation der beiden Spalten bei komplexen Änderungsverhältnissen nicht immer optimal. Die Beta von JuxtaCommons hat noch etwas Performance-Probleme und scheint noch ein Limit hochzuladender Dokumente zu haben, zudem war ja meine Anforderung, dass der Diff lokal stattzufinden habe.
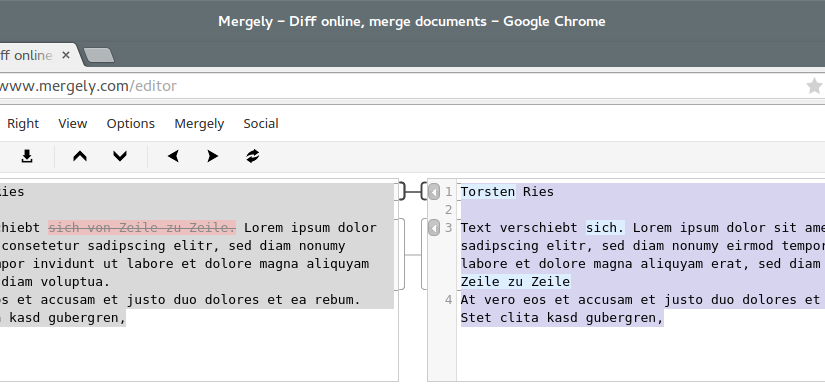
Was also tun? Es gab zwei weitere Kandidaten. Mergely und wikEd diff. Beide sind open source und lassen sich ohne Weiteres lokal ausführen. Es gibt bei der Darstellung der Textdifferenz Unterschiede, welche eine der beiden Möglichkeiten je nach Aufgabe besser geeignet erscheinen lassen dürften. Mergely gibt eine sehr übersichtliche Zwei-Spalten-Ansicht und hatte mit den technischen Artefakten und zusätzlichen Absätzen keine größeren Probleme.
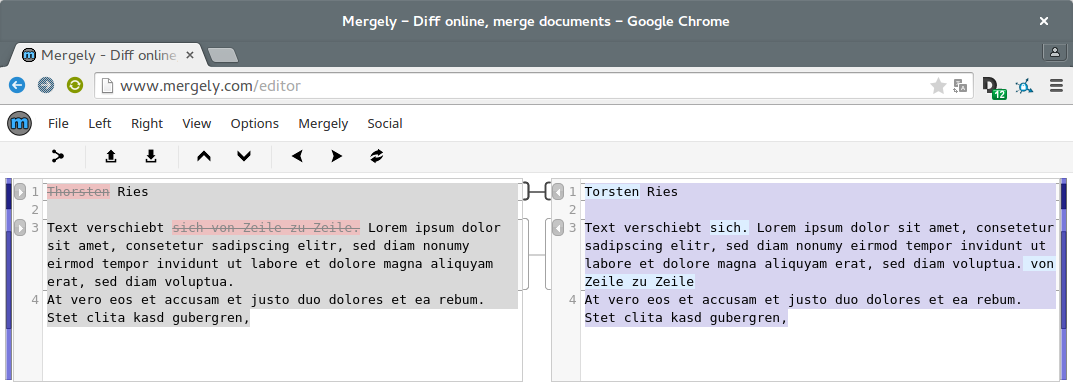 Photo credit: Thorsten Ries.3
Photo credit: Thorsten Ries.3
wikEd Diff ließ sich ebenfalls lokal nutzen, zeigte hingegen die Text-Differenz in einer zusammengeführten Spalte an, ebenfalls ohne die sonst üblichen Probleme, allerdings mit einem großen Vorteil: mit wikEd Diff wurden hier Differenzen einzelner Buchstaben innerhalb von Wörtern (und auch Interpunktion) granular korrekt abgebildet und wikEd Diff zeigte auch Verschiebungen von Text als solche an.
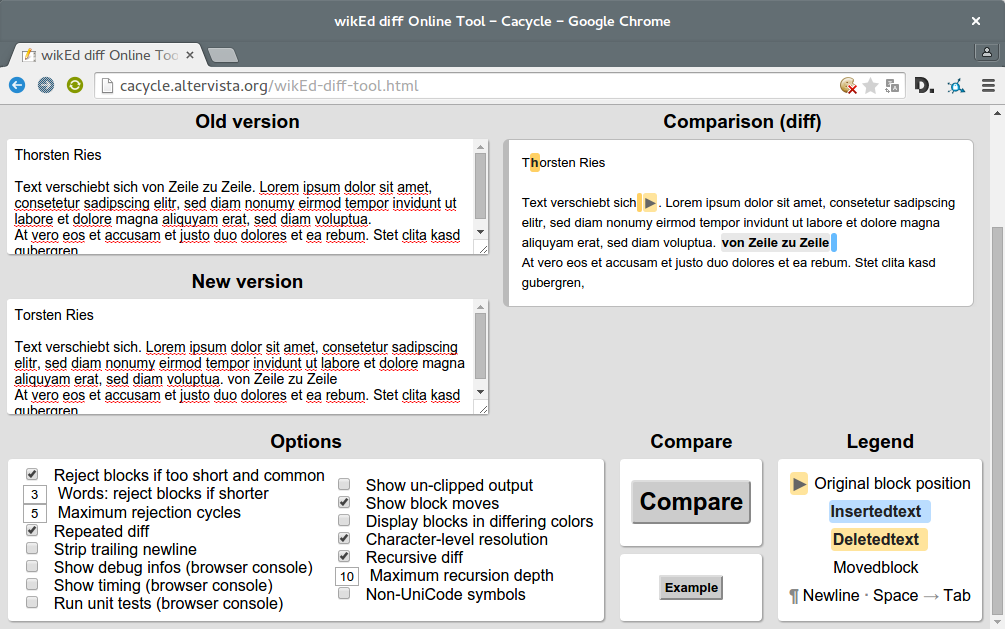 Photo credit: Thorsten Ries.4
Photo credit: Thorsten Ries.4
Mit Blick auf die Erkennung und Markierung von Änderungen auf Wortebene ist wikEd Diff momentan sogar weiter als CollateX (Python), das allerdings dafür ganz andere, prinzipielle Probleme des Text-Vergleichens und der chronologischen Anordnung bei N-Wege-Diffs löst (bzw. mehrere Algorithmen dafür anbietet) .
Meine Wahl fiel schließlich – für diesen Vortrag – auf wikEd Diff. Dies hauptsächlich, weil die Diff-Anzeige keine Probleme mit den Artefakten produzierte und die Buchstaben-Änderungen Thomas Klings in einzelnen Wörtern nicht als Ersetzungen von ganzen Wörtern erschienen. Allerdings musste ich dafür – aus philologischer Sicht bedenklich – eine Ein-Spalten-Darstellung der Textdifferenz in Kauf nehmen, die bei aller Übersichtlichkeit den Eindruck einer Versionen-Kontamination erweckt.
Hoffentlich kann dieser kleine Erfahrungsbericht als Anregung für die Entwicklung von geisteswissenschaftlichen Kollationierungs-Tools dienen. Vor allem in die weitere Entwicklung von CollateX, der Python-Variante, setze ich große Hoffnungen. Die Ergänzung von Erkennung/Darstellung von Änderungen auf Wortebene und ein GUI-Frontend für lokale Benutzung wären eine tolle Ergänzung für dieses vielversprechende Werkzeug.
Was im Zusammenhang von dynamischen Präsentationen auch noch interessant sein kann, ist natürlich, dass sich diese Timelines und TextDiff-Darstellungen auch problemlos in eine hovercraft, impress.js oder reveal.js-Präsentation einbinden lassen.
Screenshot of my own little textdiff experiment on mergely.com. ↩︎
Screenshot of demo on http://visjs.org/examples/timeline/groups/groups.html. ↩︎
Screenshot of my own little textdiff experiment on mergely.com. ↩︎
Screenshot of my own little textdiff experiment on wikEd diff. ↩︎